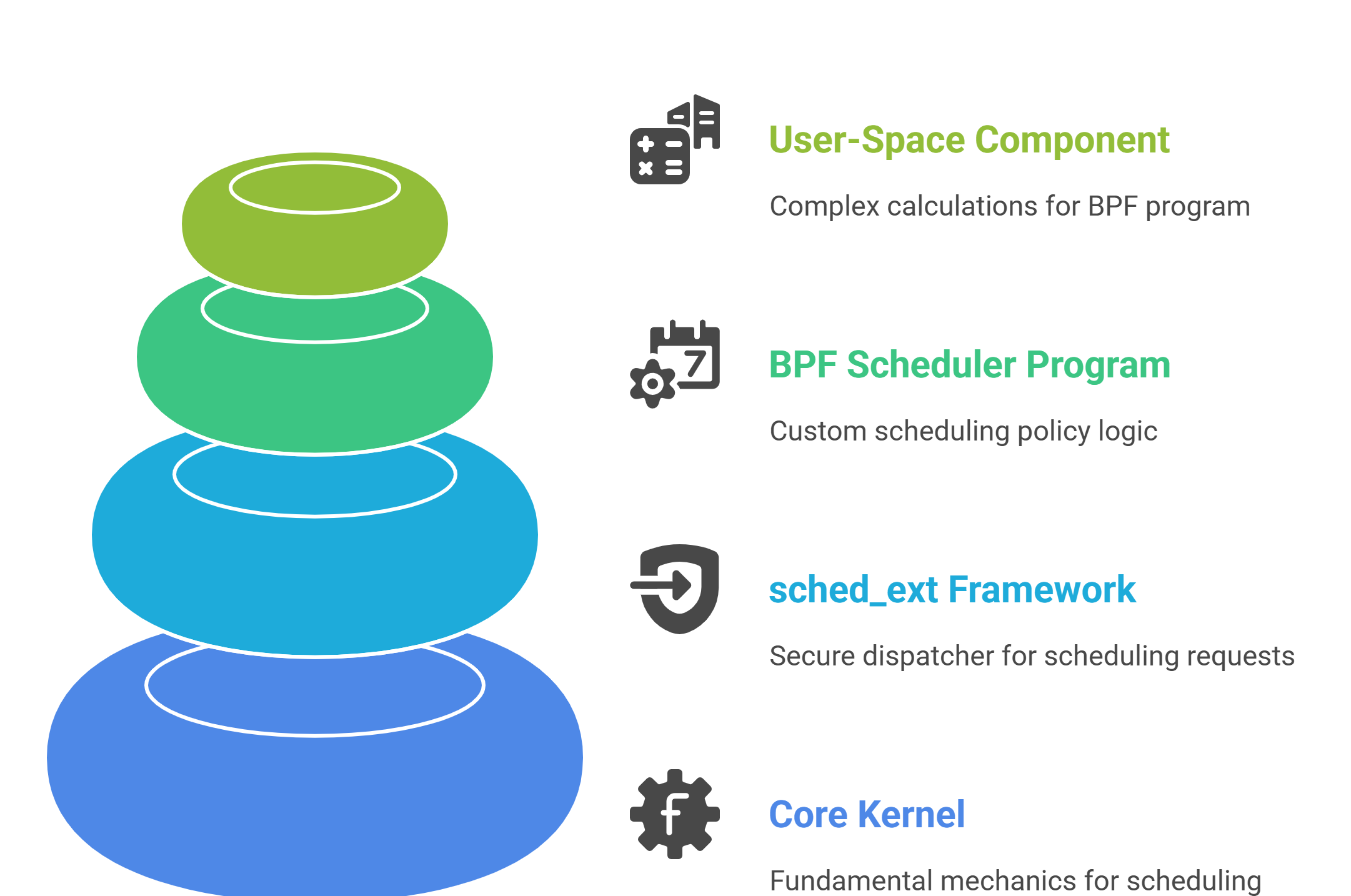
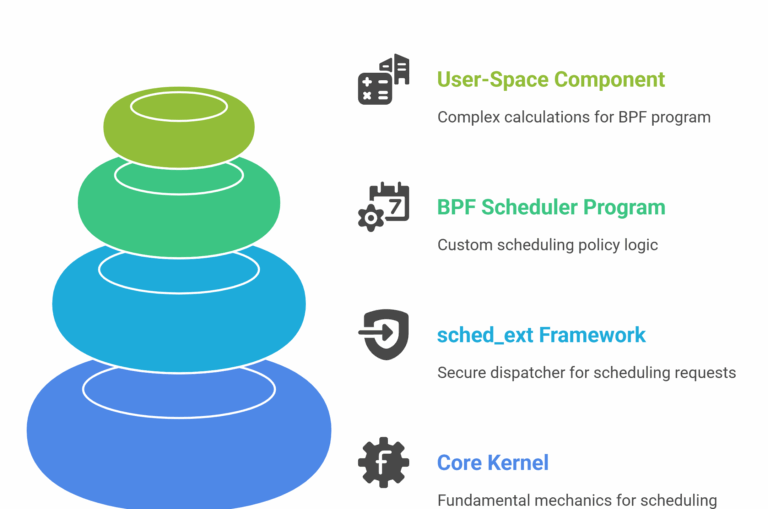
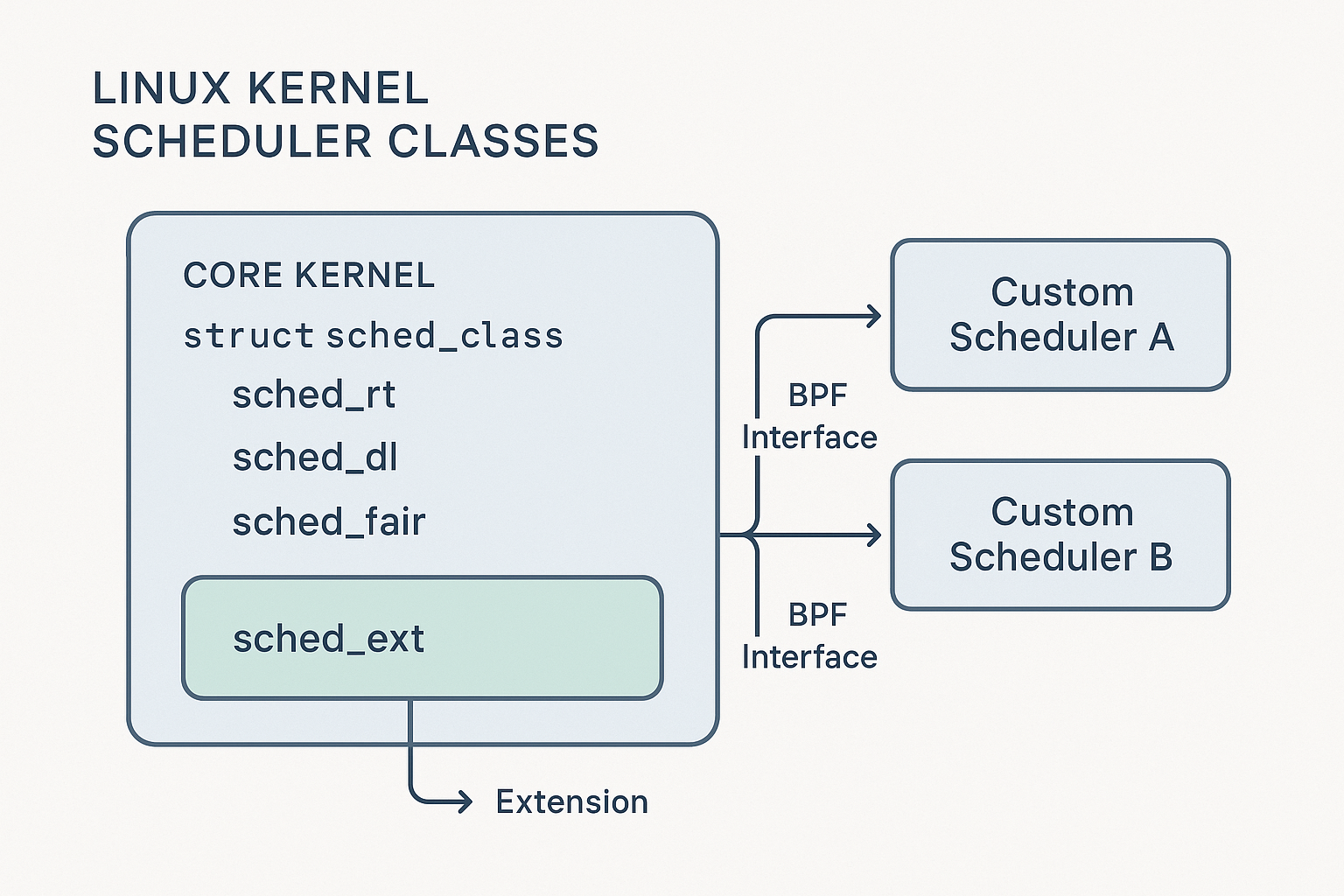
- Core Kernel: Provides the fundamental mechanics: context switching and the sched_class abstraction that allows different schedulers to coexist.
- sched_ext Framework: The “glue layer” that acts as a secure dispatcher, redirecting scheduling requests to the active BPF program and managing its lifecycle.
- BPF Scheduler Program: The developer’s custom logic. This is the scheduling policy that decides which task runs next.
- Optional User-Space Component: For complex algorithms, a user-space daemon can perform heavy calculations and feed results back to the BPF program.
The API: How the Kernel and BPF Schedulers Talk
The conversation is defined by the sched_ext_ops struct, a set of callbacks the BPF program implements. Key hooks include:
- enqueue(): The heart of the scheduler. Called when a task becomes runnable, its logic decides where the task should wait.
- dispatch(): Called when a CPU needs work. The BPF program selects a task from its internal queues and hands it off for execution.
- select_cpu(): Provides a hint to the kernel on the best CPU for a waking task, enabling smart placement.
DSQs: The Mailbox Between BPF and the Kernel
A BPF scheduler hands tasks to the kernel via a Dispatch Queue (DSQ). Think of a DSQ as a standardized mailbox. The BPF program can manage tasks using any complex data structure it wants, but when it’s time to run a task, it places it in a DSQ. The kernel only picks up work from these mailboxes. This brilliantly decouples the scheduler’s internal complexity from the kernel’s execution mechanism.
Expanding the Details – Safety, Hybrids, and Real-World Use Cases
Making It Safe: The BPF Verifier and Kernel Watchdogs
The biggest hurdle for kernel development is the risk of a single bug causing a system-wide crash. sched_ext mitigates this with a two-pronged safety model:
- Static Analysis (The BPF Verifier): Before a BPF scheduler is even loaded, the kernel’s verifier performs a rigorous static analysis. It mathematically proves that the program is safe by checking for:
- No crashes: The program cannot use null pointers or access invalid memory.
- Finite execution: The program is guaranteed to finish and cannot contain unbounded loops that would lock up the kernel.
- Secure data access: The program can only access an approved set of kernel functions and data structures. If the code fails any of these checks, the kernel refuses to load it.
- Runtime Protection (The Watchdog): Even a “safe” program can have logical bugs. What if a scheduler starves a critical task or creates a deadlock? sched_ext runs a watchdog timer. If the BPF scheduler fails to make progress or schedule a task within a certain time, the watchdog fires, automatically unloads the faulty BPF scheduler, and safely reverts all its tasks back to the default kernel scheduler (EEVDF). This acts as a crucial fail-safe, ensuring the system always remains stable.
The Hybrid Model in Action: Beyond BPF’s Limits
Let’s consider a practical example of the hybrid kernel/user-space model: a scheduler for a large-scale video transcoding service.
- The User-Space Daemon (written in Go or Rust) could analyze the dependency graph of a video file. It understands that certain frames (I-frames) must be encoded before others (P- and B-frames). It performs this complex analysis and writes high-level priorities into a BPF map shared with the kernel.
- The BPF Scheduler then reads from this map on every scheduling tick. Its job is simple and fast: pick the runnable task with the highest priority assigned by the daemon and dispatch it. It handles the real-time, low-latency decisions, while the daemon handles the complex, high-latency planning.
What Can You Build? A New Ecosystem of Schedulers
This framework unlocks the ability to build highly specialized schedulers that were previously impractical:
- Ultra-Low Latency Schedulers (Gaming & VR): A scheduler like scx_lavd can identify the main game thread and prioritize it aggressively, ensuring it never waits for CPU time, thus reducing frame time variance and eliminating stutters.
- Data Center Schedulers (Cloud & Microservices): A scheduler can be designed to enforce strict CPU isolation between co-located tenants, preventing “noisy neighbor” problems and ensuring Quality of Service (QoS) guarantees are met.
- Energy-Aware Schedulers (Mobile & IoT): On a device with performance and efficiency cores (P- and E-cores), a scheduler can be written to understand the workload. It can move background sync jobs to E-cores while ensuring that when you touch the screen, the UI thread immediately runs on a P-core for maximum responsiveness.
- Throughput Schedulers (Scientific Computing & Data Processing): For batch processing jobs, a scheduler can ignore fairness and focus entirely on maximizing throughput by batching similar tasks together to improve cache utilization.
Summary
For decades, the Linux kernel relied on monolithic, general-purpose CPU schedulers like CFS and EEVDF. While powerful, their “one-size-fits-all” approach created a ceiling on performance for specialized workloads in areas like data centers, gaming, and mobile computing, where the trade-offs between throughput, latency, and power are unique. Developing new in-kernel schedulers was a high-risk, slow process that stifled innovation.
sched_ext fundamentally changes this paradigm. Introduced in Linux 6.12, it is not a new scheduler but an extensible framework that allows developers to write and deploy custom scheduling policies as BPF programs, which can be loaded and swapped at runtime without a reboot.
The architecture cleanly separates duties into layers: the core kernel provides low-level mechanics, the sched_ext framework acts as a secure bridge, and the BPF program implements pure scheduling policy. Communication occurs through a well-defined API (sched_ext_ops) and a “mailbox” system called Dispatch Queues (DSQs), which decouples the scheduler’s internal logic from the kernel.
Crucially, sched_ext is built for safety. The BPF verifier statically proves a scheduler can’t crash the kernel, while a runtime watchdog acts as a fail-safe, automatically reverting to the default scheduler if the custom policy misbehaves. For algorithms too complex for BPF, a hybrid user-space model allows for heavyweight computations, opening the door to schedulers written in languages like Rust or Go.
This framework democratizes scheduler development, enabling a new ecosystem of highly-specialized schedulers tailored for specific outcomes—from ensuring microsecond-level latency for financial services to maximizing battery life on mobile devices. sched_ext marks a pivotal shift for Linux from a monolithic design to a flexible, safe, and workload-aware platform for the future of systems performance.